x86과 x86-64 프로세서에서는 메모리 관리 기법으로 세그먼테이션(Segmentation)과 페이징(Paging) 이 두 개의 기법을 지원합니다.
→ 세그먼테이션과 페이징의 공통점
● 주소 공간을 특정 영역으로 나눕니다.
→ 세그먼테이션과 페이징의 차이점
● 나누는 방식에서 차이가 있습니다.
● 세그먼테이션 : 전체 영역을 사람이 원하는 만큼의 크기로 나누어 관리하는 방식입니다.(케이크를 잘라먹는 것에 비유)
● 페이징 : 일정한 크기로 잘라져 있는 조각들을 사람이 원하는 만큼 모아서 원하는 크기로 관리하는 방식입니다. (미리 잘라져 있는 식빵에 비유)
메모리 관리 기법(세그먼테이션, 페이징 등)을 사용하려면 관련된 레지스터에 특정한 자료구조를 설정해야 합니다.
→ 세그먼테이션 : 세그먼트 레지스터에 어떠한 세그먼트의 시작 주소 혹은 디스크립터(Descriptor)라고 불리는 자료구조의 위치를 설정해야 합니다.
→ 페이징 : 컨트롤 레지스터 중에 CR3 레지스터에 페이지 디렉터리라고 불리는 자료구조의 물리 주소를 설정해야 사용할 수 있습니다.
모든 운영 모드에서 메모리 관리 기법(세그먼테이션, 페이징 등)을 지원하진 않습니다.
모드에 따라서 지원하지 않거나, 지원하더라도 일부 기능이 제한되는 경우도 있습니다.
그리고 같은 메모리 관리 기법이라 하더라도 모드에 따라 각 필드들의 의미가 달라지는 경우도 있습니다.
이는 x86-64 프로세서가 기존의 프로세서들과의 호환성을 위해 유지되면서 발전했기 때문입니다.
▶ 리얼 모드의 메모리 관리 방식
리얼 모드에서는 최대 1MB까지의 메모리 주소 공간을 사용할 수 있으며, 메모리 관리 기법으로는 세그먼테이션(Segmentation)만 지원합니다.
한 세그먼트의 크기는 64K로 고정이며, 세그먼트의 시작 주소는 세그먼트 레지스터에 직접 설정합니다.
세그먼테이션에서 세그먼트의 시작 주소는 코드나 메모리에 접근할 때 기준이 되는 주소로 사용됩니다.

리얼 모드는 페이징(Paging)을 사용하지 않기 때문에 물리 주소로 변환하는 방식이 간단합니다.
세그먼테이션을 거쳐 나온 주소가 바로 물리 주소가 됩니다.
리얼 모드의 세그먼테이션은 세그먼트 레지스터의 값에 범용 레지스터의 값(또는 상수 값)을 더하는 방식입니다.
(세그먼트 레지스터의 값 + 범용 레지스터의 값(또는 상수 값) = 물리 주소)
하지만 세그먼트 레지스터의 값에 범용 레지스터의 값을 더하는 것만으로는
세그먼트 레지스터와 범용 레지스터의 크기가 16bit 이기 때문에 리얼 모드에서 사용할 수 있는 최대 1MB 영역까지 접근할 수 없습니다.
그리하여 세그먼트 레지스터의 값에 16을 곱한 값을 세그먼트의 기준 주소로 사용합니다.
(세그먼트 레지스터의 값 x 16 = 세그먼트의 기준 주소)
1MB에 접근할 수 있는 이유 : 16bit의 최댓값인 65535(2^16-1) x 16(2^4) = 1048560(2^20-16)이므로 1MB에 근접

※ 리얼 모드에서 물리 주소를 구하는 계산법 정리 ※
세그먼트 레지스터의 값 x 16 = 세그먼트의 기준 주소
세그먼트의 기준 주소 + 범용 레지스터의 값(또는 상수 값) = 물리 주소
리얼 모드에서 세그먼트의 크기가 64KB인 이유는 범용 레지스터의 크기가 16bit이기 때문입니다.
16bit 프로세서에서는 32bit 레지스터가 없고, 범용 레지스터 모두 16bit 크기여서 16bit로 접근할 수 있는 범위가 65535(0xffff)이므로 세그먼트의 크기도 64KB가 된 것입니다.
▶ 보호 모드의 메모리 관리 방식
보호 모드에서는 세그먼테이션(Segmentation)과 페이징(Paging) 모두 지원합니다.
보호 모드에서도 물리 주소를 구하는 과정에서 리얼 모드에서와 같이 세그먼트의 기준 주소 + 범용 레지스터의 값(또는 상수 값)을 더해 계산하지만
리얼 모드에서와는 달리 바로 물리 주소로 바뀌는 것이 아닌 선형 주소(논리 주소)로 바뀐 뒤 페이징(Paging)을 거쳐 나온 결과 값이 물리 주소가 됩니다.
(세그먼트의 기준 주소 + 범용 레지스터의 값(또는 상수 값) = 선형 주소(논리 주소))
(선형 주소(논리 주소) -> 페이징 -> 물리 주소)
보호 모드의 세그먼테이션은 리얼 모드의 세그먼테이션보다 더 많은 기능을 제공하는데
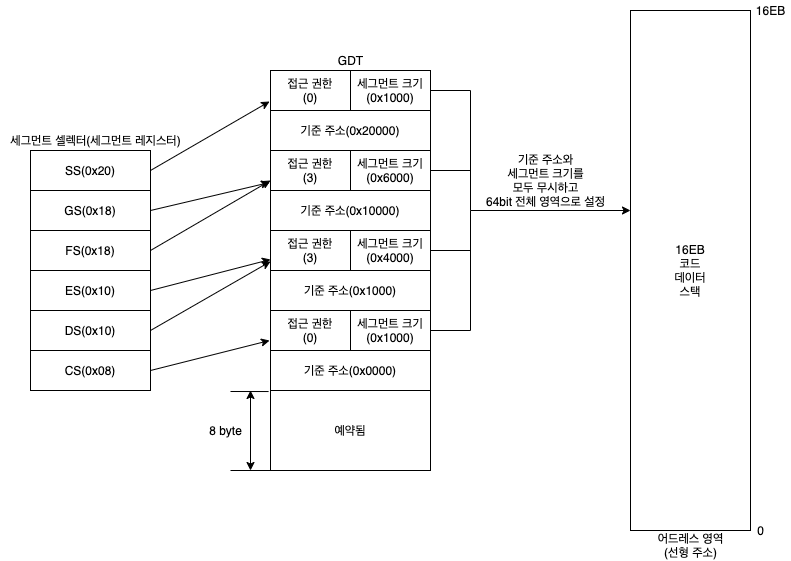
보호 모드의 세그먼테이션은 세그먼트 레지스터에 세그먼트 기준 주소를 직접 설정하지 않고, 세그먼트 디스크립터의 위치(Offset)를 설정하는 방식입니다.
보호 모드에서 세그먼트 레지스터의 명칭은 세그먼트 디스크립터를 선택한다는 의미로 세그먼트 셀렉터로 바뀌었습니다.
메모리 영역의 정보를 저장하는 자료구조인 디스크립터는 여러 종류가 있고, 그중 세그먼트에 관련된 정보를 나타내는 세그먼트 디스크립터가 있습니다.
세그먼트 디스크립터에는 시작 주소와 크기, 권한(Privilege), 타입(Type) 등의 정보가 있습니다.
아래의 그림은 세그먼트 디스크립터의 구조인데
13bit ~ 14bit는 DPL(특권 레벨, Descriptor Privilege Level)이라 하여 해당 세그먼트에 접근하기 위한 최소한의 권한을 나타내며, 0 ~ 3 사이의 값을 가집니다.
숫자가 작을수록 권한이 높고, CPL(현재 수행 중인 특권 레벨, Current Privilege Level)이 디스크립터에 설정된 권한과 같거나 더 높은 권한을 의미하는 더 작은 숫자여야 합니다.
만약, 조건을 만족하지 않으면 프로세서는 예외를 발생시켜 문제가 발생했다고 알려줍니다.
또한 접근하는 주소가 세그먼트의 크기를 넘어서는 경우도 예외가 발생합니다.


메모리상에 위치하는 자료구조의 일종인 세그먼트 디스크립터는
최대 8192개의 디스크립터를 포함할 수 있고, 연속된 디스크립터의 집합체이자 테이블 형태의 자료구조인 GDT(Global Descriptor Table)에 모여있고
세그먼트 셀렉터(세그먼트 레지스터)는 세그먼트 디스크립터의 위치를 가리키는데 사용됩니다.
GDT도 메모리에 위치하는 자료구조로 프로세서한테 GDT의 위치를 직접 알려야 하고
GDT의 위치와 관련된 레지스터는 프로세서 내의 컨트롤 레지스터들 중 GDTR(Global Descriptor Table Register) 레지스터이며
16bit GDT 크기 필드와 32bit 기준 주소 필드로 구성된 자료 구조의 물리 주소를 넘겨받습니다.
그리고 프로세서는 GDT의 위치를 빠르게 넘기기 위해 이를 내부에 저장해두었다가 세그먼트 셀렉터(세그먼트 레지스터)를 통해 주소에 접근할 때마다 GDT의 위치를 찾는데 이용합니다.
프로세서는 실제 메모리에 접근할 때 선형 주소(논리 주소)를 기반으로 물리 주소를 계산합니다.
보호 모드에서는 리얼 모드에서와는 달리 세그먼트의 크기가 64KB로 고정되어 있지 않아 크기를 지정할 수 있습니다.
세그먼트의 크기는 해당 세그먼트의 주소에 접근할 때 이용되며
기준 주소에 더해질 값(범용 레지스터의 값 또는 특정 상수 값)은 세그먼트의 크기(세그먼트 디스크립터에 정의한 크기)를 넘으면 안 됩니다.
더해지는 값이 세그먼트의 크기를 넘게 된다면 프로세서는 세그먼트의 접근 권한을 위반한 경우와 마찬가지로 예외를 통해 오류가 발생했음을 알려줍니다.

보호 모드에서 세그먼테이션을 거쳐 나온 선형 주소는 물리 주소와 일치할 수도, 일치하지 않을 수도 있습니다.
선형 주소는 페이징 기법의 입력 값이 되며, 페이징을 사용하지 않는다면 선형 주소는 물리 주소와 1:1로 대응됩니다.
작고 간단한 OS는 대부분 페이징을 사용하지 않거나, 사용은 하되 선형 주소와 물리 주소가 1:1로 대응하도록 합니다.
선형 주소와 물리 주소가 1:1로 대응되면, OS의 관리 기능을 작고 가볍게 유지할 수 있고, 메모리 구조가 직관적이어서 디버깅이 편합니다.

위의 사진은 선형 주소가 물리 주소와 1:1로 대응되는 사진입니다.
위의 사진을 보면 16 bit selector의 값 + 32-bit offset 한 값이 32-bit linear address(32-bit 선형 주소)가 되고 이 값이 바로 물리 주소로 바뀝니다.
아래의 사진은 세그먼테이션과 페이징의 관계를 나타낸 사진입니다.

페이징(Paging) 기법은 물리 메모리를 페이지(Page)라고 불리는 일정한 크기로 나누고, 나눠 놓은 페이지로 선형 주소와 물리 주소를 연결하는 방식입니다.
페이징 기법을 이용하면 디버깅은 어려워지지만 실제 물리 메모리보다 선형 주소의 영역이 더 크더라도 물리 페이지만 잘 연결하면 사용이 가능하기에 공간을 더 많이 사용할 수 있습니다.
또한, 같은 물리 페이지를 여러 선형 주소에 연결하여 응용프로그램끼리 공유하는 메모리를 쉽게 처리할 수 있고
반대로 페이징 자료구조를 따로따로 생성하여 물리 메모리에 중복되지 않게 연결해줌으로써 응용 프로그램마다 독립적인 주소 공간을 보장할 수도 있습니다.
그리고 최신 OS는 이러한 기능 이용하여 응용프로그램에 독립된 주소 공간 보장, 공유 메모리, 요구 페이징, 공유 라이브러리 등의 기능을 구현합니다.

위의 사진은 2개의 응용 프로그램이 4GB 크기의 독립적인 주소 공간을 가질 때 이를 1GB 크기의 물리 메모리에 어떻게 연결하는지를 나타낸 것이다.
→ 보호 모드에서 페이징은 페이지 크기에 따라 두 가지 방식으로 구분합니다.
● 물리 메모리를 4KB 크기의 페이지로 나누고, 선형 주소를 3단계로 구분하는 방식
● 물리 메모리를 4MB 크기의 페이지로 나누고 선형 주소를 2단계로 구분하는 방식
→ 프로세서에서 지원하는 물리 주소 확장 기능을 사용하면 4가지 방식으로 구분합니다.
● 기존의 두 가지 방식
● 물리 메모리를 4K 크기의 페이지로 나누고, 선형 주소를 4단계로 구분하는 방식
● 물리 메모리를 2MB 크기의 페이지로 나누고, 선형 주소를 3단계로 구분하는 방식
※ 물리 메모리를 4KB 크기의 페이지로 나누고, 선형 주소를 3단계로 구분하는 방식(이하 3단계 페이징)으로 설명
3단계 페이징은 선형 주소를 디렉터리, 테이블, 오프셋 이렇게 세 부분으로 나누며 물리 메모리를 4KB 크기의 페이지로 나누어 관리하는 방식입니다.
생성되어 있는 선형 주소의 정보를 이용하여 선형 주소의 디렉터리와 테이블 부분은 각각 페이지 디렉터리와 페이지 테이블에 있는 엔트리의 위치를 나타내고
페이지 디렉터리와 페이지 테이블은 GDT와 마찬가지로 메모리 공간에 있는 자료구조이기 때문에 페이징 처리 과정에서 해당 테이블을 사용하려면 프로세서에게 직접 위치를 알려줘야 하는데
페이징에서는 컨트롤 레지스터들 중 CR3 레지스터를 사용하고, CR3 레지스터는 페이지 디렉터리의 시작 주소를 가리키며, 페이지 디렉터리 엔트리의 위치 계산에 사용합니다.


페이지 디렉터리 엔트리와 페이지 테이블 엔트리 모두 크기가 4byte입니다.
페이지 크기는 최소 4KB이기 때문에 페이지 디렉터리 엔트리, 페이지 테이블 엔트리 모두
bit 0 ~ bit 11까지는 속성 필드로 사용되고
bit 12 ~ bit 31까지는 기준 주소를 나타내는 데에 사용되며
몇몇 필드를 제외하면 두 엔트리는 거의 비슷합니다.
→ 위의 속성 필드들 중 U(bit 2 ~ bit 3) 필드는 U/S(User/Supervisor) 라고도 하며, 해당 페이지에 접근할 수 있는 권한을 나타내며 0과 1로 설정할 수 있습니다.
● 0 - 유저 애플리케이션 레벨(3)을 제외한 모든 레벨에서 접근 가능.
● 1 - 유저 애플리케이션 레벨 이상에서 접근 가능함을 의미함으로써 모든 레벨에서 접근 가능
페이지와 세그먼테이션의 보호 기능을 조합하면 메모리 모델은 단순하게 유지하면서 커널 영역과 유저 영역을 구분할 수 있습니다.

→ 보호 모드에서 선형 주소의 구조는 위의 그림과 같습니다.
● 최상위 비트부터 디렉터리 오프셋 10bit, 테이블 오프셋 10bit, 페이지 오프셋 12bit
디렉터리와 테이블의 오프셋이 10bit이기 때문에 페이지 디렉터리와 페이지 테이블의 엔트리 수는 총 1024(2^10) 개이며
페이지 오프셋은 4KB 크기인 페이지의 오프셋을 나타내기 위해 12bit이기 때문에 최댓값이 4KB(4096, 2^12)입니다.
페이지 디렉터리 엔트리의 값은 다음에 위치하는 페이지 테이블의 시작 주소를 나타내고
페이지 테이블 엔트리 값은 다음에 위치하는 페이지의 시작 주소를 나타냅니다.
그리고 페이지의 시작 주소 값에 선형 주소의 오프셋을 더하여 물리 주소를 구합니다.
→ 선형 주소에서 물리 주소를 구하는 과정은 위의 사진을 바탕으로 다음과 같습니다.
① CR3 레지스터에 설정된 주소로 페이지 디렉터리의 시작 주소를 찾습니다.
② 페이지 디렉터리의 시작 주소에 선형 주소의 디렉터리 오프셋을 이용하여 해당 디렉터리 엔트리를 찾습니다.
(디렉터리 엔트리에 설정된 값이 페이지 테이블의 시작 주소)
③ 페이지 테이블의 시작 주소에 선형 주소의 테이블 오프셋을 이용하여 해당 페이지 테이블 엔트리를 찾습니다.
(페이지 테이블 엔트리에 설정된 값이 4KB 페이지의 시작 주소)
④ 페이지의 시작 주소에 선형 주소의 페이지 오프셋 값을 더하여 실제 물리 주소로 변환합니다.
▶ IA-32e 모드의 메모리 관리
※ IA-32e 모드의 서브 모드 중 32bit 호환 모드는 보호 모드와 동일한 동작이므로 64bit 모드로 설명합니다.
IA-32e 모드의 64bit 모드(이하 IA-32e 모드)는 64Bit이므로 사용할 수 있는 메모리 최대 주소 값은 16EB(Exa Byte, 2^64)로 보호 모드의 2^32 보다 10억 배 이상의 공간을 사용할 수 있습니다.
(Exa Byte = 2 ^ 60 byte)
IA-32e 모드의 세그먼테이션은 보호 모드의 세그먼테이션과 큰 차이는 없지만 한 가지 차이점으로는
세그먼트 디스크립터에 설정된 기준 주소와 크기에 관계없이 모든 세그먼트가 기준 주소는 0이고, 크기는 64bit 전체로 설정됩니다.
보호 모드에서 사용하던 세그먼트 디스크립터는 32bit 어드레스만 저장하게 설계되었기 때문에
64bit 어드레스 지원을 위해서 디스크립터를 확장하지 않고 강제로 값을 고정하였습니다.
하지만 IA-32e 모드에서는 위의 방식을 사용하지 않습니다.
따라서 OS를 설계할 때 IA-32e 모드에서는 선형 주소를 기준 주소가 다른 여러 개의 세그먼트로 구분할 수 없음을 고려해야 합니다.
(32bit os를 개발해본 적이 있고, 해당 OS가 커널 영역과 유저 영역을 세그먼트 기준 주소로 구분하고 있다면 IA-32e 모드에서는 유효하지 않으므로 페이징이나 다른 방법을 고려해야 합니다.)
그리고
IA-32e 모드는 32bit 호환 모드와 64bit 모드 이렇게 두 가지의 서브 모드가 존재하므로
이를 구분하기 위해 코드 세그먼트 디스크립터에 L 필드(bit21)가 추가되었습니다.
L 필드를 0으로 설정하면 32bit 호환 모드로 동작하고, 1로 설정하면 64bit 모드로 동작하기에 굳이 보호 모드로 돌아가지 않고도 32bit 코드를 실행할 수 있는 것입니다.
※ IA-32e 모드의 서브 모드가 32bit 호환 모드일 경우에는 어드레스 변환 방식이 보호 모드와 같습니다.
IA-32e 모드의 페이징은 주소 공간이 64bit로 늘어났으므로 PAE(물리 주소 확장 기능, Physical Address Extension) 기능이 자동으로 활성화됩니다.
(PAE 기능 : 4GB 이상의 물리 메모리를 32bit mode에서 사용할 수 있도록 하는 기능)
주소 공간이 늘어났기 때문에 기존의 4KB 크기의 페이지는 5단계로, 2MB 크기의 페이지는 4단계로 변경됩니다.
→ 이로 인해 새롭게 추가된 테이블은 다음과 같습니다.
● PML4(페이지 맵 레벨 4, Page Map Level 4 Tabel)
● PDPT(페이지 디렉터리 포인터 테이블, Page-Directory-Pointer-Table)
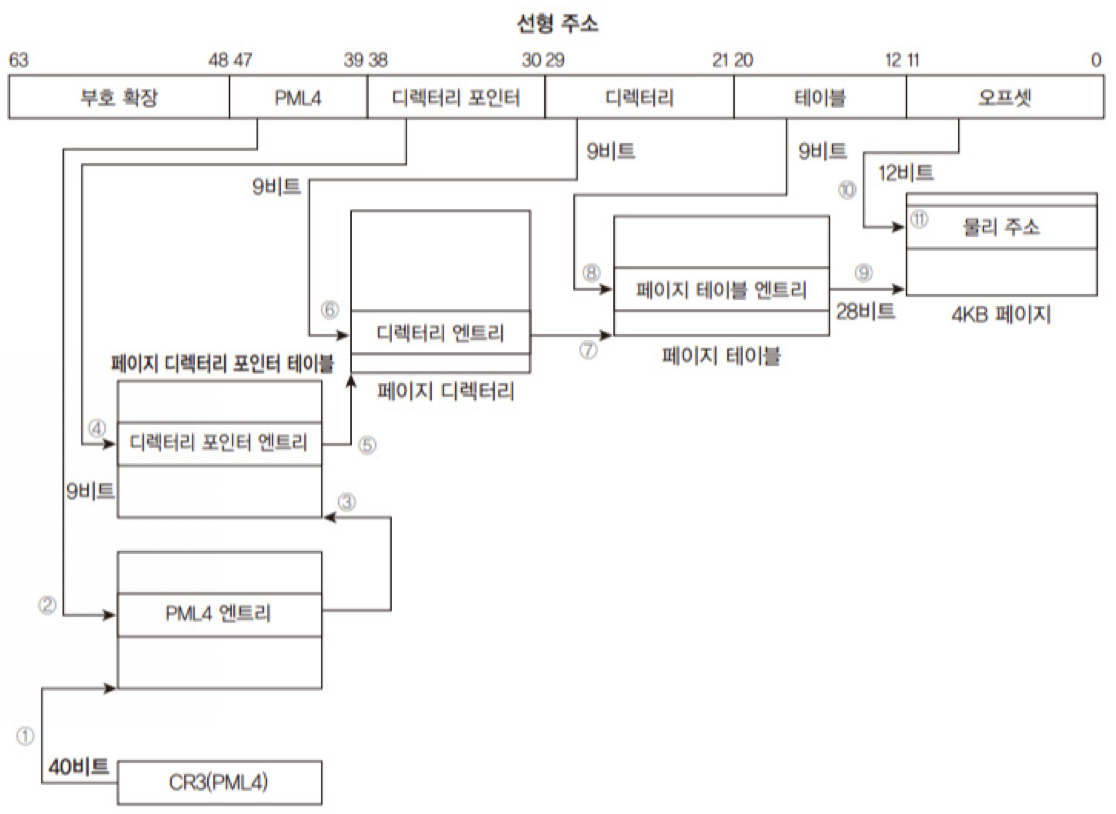
→ 위의 과정은 IA-32e 모드에서 5단계 페이징과 어드레스 변환 과정을 나타낸 사진입니다.
① CR3 레지스터에서 PML4의 시작 주소를 찾습니다.
② PML4의 시작 주소에 선형 주소의 PML4 오프셋을 이용하여 해당 PML4 엔트리를 찾습니다.
③ (PML4 엔트리에 설정된 값이 PDPT(페이지 디렉터리 포인터 테이블)의 시작 주소)
④ PDPT의 시작 주소에 선형 주소의 디렉터리 포인터 오프셋을 이용하여 디렉터리 포인터 엔트리를 찾습니다.
⑤ (디렉터리 포인터 엔트리에 설정된 값이 페이지 디렉터리의 시작 주소)
⑥ 페이지 디렉터리의 시작 주소에 선형 주소의 디렉터리 오프셋을 이용하여 해당 디렉터리 엔트리를 찾습니다.
⑦ (디렉터리 엔트리에 설정된 값이 페이지 테이블의 시작 주소)
⑧ 페이지 테이블의 시작 주소에 선형 주소의 테이블 오프셋을 이용하여 페이지 테이블 엔트리를 찾습니다.
⑨ (페이지 테이블 엔트리에 설정된 값이 4KB 페이지의 시작 주소)
⑩ 페이지의 시작 주소에 선형 주소의 페이지 오프셋 값을 더하여 실제 물리 주소로 변환합니다.
ⓐ 실제 물리 주소
보호 모드에서와의 차이점은 각 테이블의 인덱스(위치)가 9bit로 줄어들어 엔트리의 개수가 512(2^9) 개로 줄었습니다.
위의 그림을 보면 선형 주소 중 bit 48 ~ bit 63 까지는 부호 확장으로 채워지므로, 실제로 변환에 사용되는 부분은 bit 48까지이며, 최대로 표현 가능한 주소 범위가 256TB(2^48)입니다.
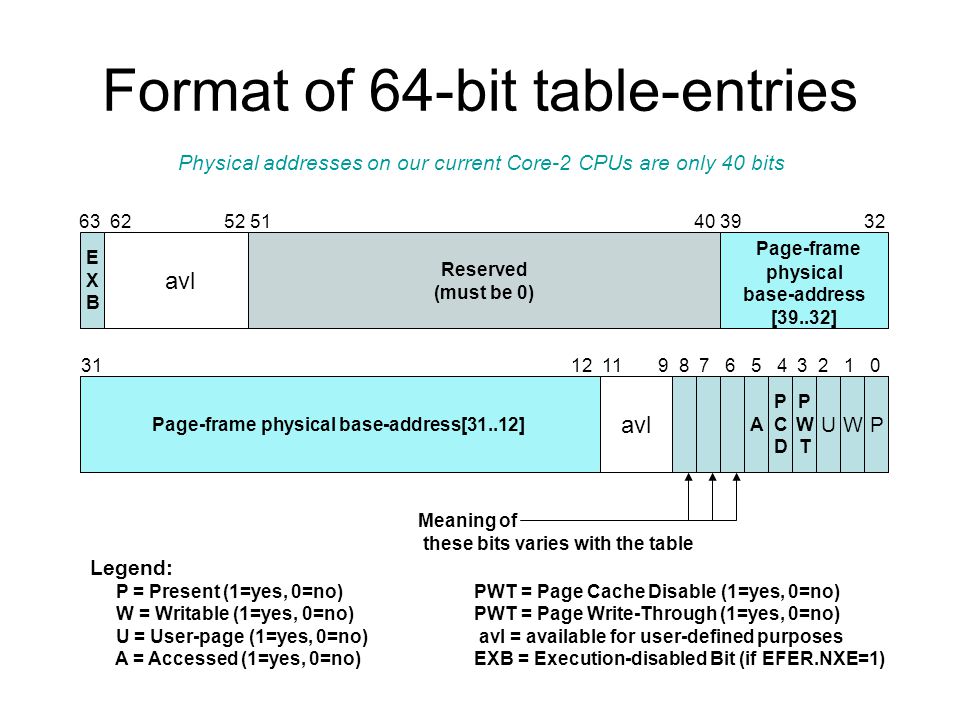
그렇다고 하여 선형 주소의 48bit 모두가 물리 주소로 변환되진 않고, 프로세서가 40bit의 물리 주소를 지원하는 경우에만 최대 1TB(2^40)의 물리 메모리를 사용할 수 있습니다.
위의 사진을 보면, bit 40 ~ bit 51 까지는 모두 0으로 예약되어 있고, bit 0 ~ bit 39까지 총 40bit 물리 메모리를 사용할 수 있습니다.
하지만, 40bit 물리 메모리를 지원하는 프로세서는 대부분 서버용 프로세서이기 때문에 일반 PC에서 사용하는 프로세서는 보통 1TB 이하(64GB, 128GB 등)만 지원합니다.
그래서 일반 PC에서는 40bit의 어드레스만으로도 충분합니다.
그리고 위의 사진에서와 같이 IA-32e 모드의 페이지 엔트리는 어드레스가 64bit로 늘어남으로 인해 8byte로 늘어났습니다.
하위 4byte(bit 0 ~ bit 31)는 보호 모드와 구조가 같습니다.
상위 4byte(bit 32 ~ bit 63)는 기준 주소 필드(bit 32 ~ bit 39), 예약된 영역(bit 40 ~ bit 51), 임의로 사용 가능한 영역(bit 52 ~ bit 62), EXB(bit 63)로 구성되어 있습니다.
이 중 EXB 필드는 해당 페이지에서 명령어 실행 기능을 활성화 / 비활성화할 수 있습니다.
이 기능을 이용하면 데이터 영역에서 명령어가 실행되는 것을 막을 수 있으며, OS를 더 안전하게 만들 수 있습니다.
데이터 영역에서 명령어가 실행되는 것이 문제인 이유
데이터 영역은 프로그램 코드가 포함되지 않고, 데이터만 있는 영역이기 때문입니다.
보통의 프로그램은 크게 코드 영역과 데이터 영역으로 구분되며, 정상적인 프로그램이라면 데이터 영역에서 명령어가 실행되지 않지만, 간혹 데이터 영역에서 명령어가 실행되는 경우가 있습니다.
대표적인 예시로는 해킹을 받았을 때인데, BOF와 SBOF(Stack BOF)는 버퍼나 스택에 프로그램 코드를 삽입한 후 해당 영역의 최댓값 이상으로 데이터를 밀어 넣어 강제로 코드를 실행하는 기법으로, 이때 삽입된 코드는 버퍼나 스택 안에 있으며, 두 영역은 모두 데이터 영역에 포함됩니다.
만약 데이터 영역의 페이지에 EXB 속성을 활성화했다면, 명령어가 실행되는 순간 페이지 폴트 예외가 발생하고 프로그램 실행이 중지되므로 공격을 막을 수 있게 되는 것입니다.
이상으로 리얼 모드(16bit), 보호 모드(32bit), IA-32 모드의 서브 모드 중 64bit 모드에서의 메모리 관리 기법들에 대한 설명이었습니다.
'시작하지 말았어야 했던 것 > 64비트 멀티코어 OS' 카테고리의 다른 글
| 64비트 멀티코어 OS[3] - 2. Eclipse 프로젝트 생성과 Makefile 생성 (0) | 2021.02.11 |
|---|---|
| 64비트 멀티코어 OS[3] - 1. 부팅과 부트로더란 (0) | 2021.02.10 |
| 64비트 멀티코어 OS[2] - 1. 운영 모드와 레지스터 (0) | 2021.02.06 |
| 64비트 멀티코어 OS[1] - 2. 우분투 개발 환경 구축 (0) | 2021.01.27 |
| 64비트 멀티코어 OS[1] - 1. 윈도우 개발 환경 구축 (8) | 2021.01.14 |