인터럽트 방식은 프로세서가 컨트롤러를 주기적으로 확인하여 데이터가 있는지 확인할 필요가 없습니다.
인터럽트 방식은 컨트롤러에 데이터가 있거나 데이터를 전송할 수 있을 때 인터럽트를 통해 이를 알려주므로 상대적으로 프로세서를 덜 사용합니다.
반면에 폴링 방식은 주기적으로 확인하므로 프로세서의 소모가 심하고, 확인하는 주기에 비례하여 데이터가 수신되는 시간이 길어집니다.
이러한 차이는 멀티태스킹 환경에서 확연히 드러나는데, 멀티태스킹 환경은 여러 프로그램이 프로세서를 나누어 사용하므로 프로그램의 수가 늘어날수록 프로세서를 할당받는 주기가 길어집니다.
프로그램이 폴링 방식을 사용한다면 태스크 수에 비례하여 폴링 주기가 길어지므로 데이터를 원활하게 처리할 수 없습니다.
그렇기에 인터럽트 방식을 사용하면 프로그램의 수와 관계없이 데이터를 처리할 수 있으므로 많은 디바이스 드라이버를 인터럽트 기반으로 작성합니다.
→ 인터럽트 핸들러와 통신 방법
이번 내용에서 최종 목표는 키보드 디바이스 드라이버를 인터럽트 방식으로 변경하는 것입니다.
이를 위해서 셸 코드의 키 처리 부분을 인터럽트 핸들러로 옮겨야 하지만, 인터럽트의 장점 때문에 한 가지 처리할 부분이 있습니다.
인터럽트는 발생 시점을 예측할 수 없으므로 인터럽트가 발생했을 때 코드의 어느 곳을 실행하는지 알 수 없는데, 셸 코드가 키를 처리하려면 인터럽트 핸들러가 읽은 키 값이 필요합니다.
일반적으로 가장 많이 사용하는 방법으로는 데이터를 저장하는 버퍼를 통하는 것으로, 인터럽트 핸들러는 디바이스에서 읽은 데이터를 버퍼에 저장하고, 프로그램은 버퍼를 확인하여 이를 처리함으로써 데이터를 전달할 수 있습니다.
참고)
컨트롤러에서 읽는 대신 버퍼를 계속 확인해야 하므로 셸의 입장에서는 기존의 폴링 방식과 차이가 없을 수도 있지만, 프로세서 외부에 연결된 컨트롤러에서 데이터를 확인하는 시간보다 메모리에서 확인하는 시간이 훨씬 짧고, 멀티태스킹 환경에서 얻는 이점을 고려하면 인터럽트 방식이 폴링 방식보다 더 유용합니다.
→ 큐(Queue)
큐 : 데이터가 입력된 순서로 출력하는 순차적 자료구조입니다.
먼저 들어온 데이터가 먼저 나가는 특성 때문에 FIFO(First-In, First-Out)라고도 불리며, 데이터를 저장하는 버퍼로 많이 사용됩니다.
큐(Queue)는 삽입(put)과 제거(get) 두 가지 기능만 제공하며, 데이터를 순차적으로 처리하므로 구현이 쉽고 간단합니다.
아래는 큐의 이런 특징을 예를 들어 나타낸 것입니다.
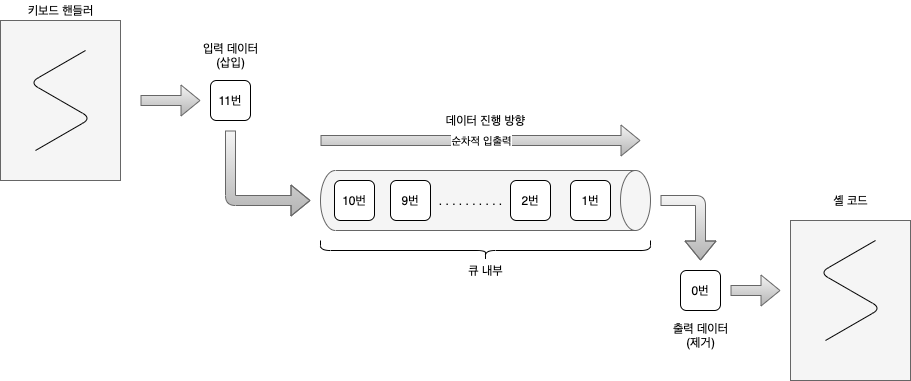
FS64 OS는 큐를 다양한 목적으로 사용하므로 자료구조도 다양합니다.
만약 특정 자료구조만 처리할 수 있게 구현한다면 데이터의 종류에 따라 큐를 구현해야 하므로 좋은 해결책이라 볼 수 없기 때문에 이번 내용에서는 이런 문제를 해결하기 위해 범용으로 사용할 수 있는 큐를 설계했습니다.
C++ 언어의 상속과 클래스를 이용하면 이런 부분을 쉽게 처리할 수 있지만, C언어로도 가능합니다.
→ 범용 큐 설계
코드를 작성하기 위한 설계도가 필요하니 범용 큐의 구조와 알고리즘을 알아봅니다.
큐의 선입선출 방식은 데이터를 저장하는 버퍼와 삽입, 제거 위치를 가리키는 두 개의 인덱스를 사용해 순차적으로 증가시키는 방식을 사용하면 됩니다.
범용적인 큐의 범용적이라는 말은 다시 풀이하자면 다양한 크기의 자료구조를 다룰 수 있다는 말과 같습니다.
다양한 크기의 자료구조를 처리하려면, 큐의 데이터를 1byte로 처리하는 것이 아니라 여러 데이터를 묶어서 처리하는 것입니다.

위의 그림은 구현할 큐의 알고리즘을 나타낸 것이며, 자료구조의 크기를 3바이트라고 가정하고 3바이트 단위로 묶어 처리하는 방법을 나타냈습니다.
삽입 위치와 제거 위치를 사용하여 삽입과 제거를 수행하고, 큐에 삽입 동작을 수행하면 데이터를 삽입한 뒤에 삽입할 위치를 다음 위치로 이동하며, 제거하는 동작도 데이터를 제거하고 나서 제거할 위치를 다음으로 이동합니다.
삽입하거나 제거할 위치를 변경할 때는 두 가지 상황을 고려해야 합니다.
1. 삽입이나 제거한 뒤에 위치가 버퍼의 최댓값을 초과하는 경우
2. 다른 하나는 제거한 뒤에 두 위치가 같아지는 경우
삽입과 제거를 반복하다 보면 두 인덱스가 계속 증가하므로 최댓값을 초과할 때 다시 인덱스를 버퍼의 처음으로 되돌리는 방법으로 삽입하거나 제거할 위치가 버퍼의 최댓값을 초과할 때는 쉽게 처리할 수 있습니다.
버퍼의 인덱스를 돌아가면서 사용하는 이런 방식을 환형 큐(Circular Queue)라고 합니다.
삽입 위치와 제거 위치가 같아지는 경우는 다시 두 가지 상황을 고려해야 합니다.
1. 초기 상태이거나 제거 동작을 수행한 후 두 위치가 같아지는 경우
이 경우는 큐에 데이터가 남아 있지 않으므로 제거 동작을 수행하기 전에 이러한 상태인지 확인해야 합니다.
2. 삽입 동작을 수행한 후 두 위치가 같아지는 경우
이 경우는 반대로 큐가 가득 차 있는 상태이므로 삽입 동작을 수행하기 전에 상태를 확인해야 합니다.
→ 범용 큐 구현과 사용 방법
실제 삽입/제거 함수를 살펴보기 전에 다양한 데이터를 다룰 수 있게 자료구조를 먼저 정의합니다.
아래는 큐에 대한 정보를 관리하는 자료구조를 나타낸 코드입니다.
큐를 구성하는 데이터의 크기와 삽입할 수 있는 최대 개수, 버퍼로 사용할 주소와 삽입 혹은 제거할 인덱스가 들어있습니다.

큐 자료구조에 포함된 bLastOperationPut 필드는 위에서 설명했던 삽입 위치와 제거 위치가 같아지는 경우를 처리하기 위해 추가한 필드로, 이 필드는 삽입 동작을 수행했을 때 TRUE로 설정되고, 제거 동작을 수행했을 때 FALSE로 설정됩니다.
아래는 위의 자료구조를 바탕으로 초기화를 수행하는 함수와 삽입 및 제거를 수행하는 함수입니다.
큐를 초기화하는 함수는 큐 버퍼 주소와 데이터의 크기를 설정하고 나머지 필드를 기본값(0)으로 설정합니다.

큐에 삽입하는 함수와 제거하는 함수는 삽입 또는 제거할 수 있는지 확인하는 부분과 데이터를 처리하는 부분, 그리고 인덱스를 변경하고 삽입 또는 제거 동작임을 기록하는 부분으로 구분됩니다.
아래는 큐에 데이터를 삽입하고 제거하는 함수의 코드를 나타낸 것입니다.


데이터를 복사하는 부분을 제외한 나머지 부분은 모두 설명했기에 데이터 처리 부분만 살펴봅니다.
데이터를 처리하는 과정에서 주의해야 할 점은 삽입 또는 제거 인덱스를 이용하여 버퍼에 접근할 때 초기화 시점에서 설정한 데이터 크기를 반영해야 한다는 점입니다.
만약 초기화 함수를 수행할 때 데이터의 크기를 3바이트로 설정했다면 삽입할 인덱스가 4일 때 실제로 데이터가 위치하는 버퍼의 바이트 오프셋은 12가 되기 때문에 인덱스로 버퍼에 접근할 때 항상 이를 유의해야 합니다.
참고)
범용 큐를 사용할 때 주의할 점은 버퍼의 크기가 파라미터로 넘어온 iMaxDataCount와 iDataSize를 곱한 값보다 반드시 크거나 같아야 합니다.
삽입 및 제거 함수는 iDataSize를 기본 단위로 하여 iMaxDataCount까지 접근하기 때문에 버퍼의 크기가 이보다 작으면 버퍼의 범위를 벗어나 데이터를 삽입 또는 제거할 것이기에 예기치 못한 결과를 가져올 수 있습니다.
위에서 만든 큐를 사용하려면 삽입이나 제거 동작을 수행하기 전에 반드시 먼저 초기화를 수행해야 한다는 점을 명심해야 합니다.
초기화하지 않은 상태에서 큐를 사용하면 잘못된 주소에 접근하여 최악에는 OS가 멈추거나 PC가 리부팅될 수 있습니다.
아래는 임의의 크기를 가지는 자료구조인 TEMPDATA를 최대 100개까지 관리할 수 있는 큐를 생성하고 사용하는 코드입니다.

키보드 디바이스 드라이버 업그레이드
인터럽트 방식을 사용하면 태스크가 디바이스를 폴링 할 필요가 없다는 장점이 있는 반면에 언제 인터럽트가 발생하여 데이터가 수신될지, 수신된 데이터를 태스크가 언제 처리할지를 알 수 없는 단점이 있습니다.
여기서 문제는 멀티태스킹 환경이 되면 태스크끼리 프로세서를 나누어 사용하므로 수신된 데이터를 처리하기까지 시간이 일정하지 않기 때문에 인터럽트에서 수신된 데이터를 태스크가 처리할 때까지 보관할 영역이 필요합니다.
인터럽트 핸들러와 태스크를 연결해 줄 큐가 준비되었으니, 이제 키 정보를 저장하는 큐를 생성하고, 이를 이용하여 폴링 방식으로 작성된 키보드 디바이스 드라이버를 인터럽트 방식으로 업그레이드합니다.
→ 키 정보를 저장하는 자료구조와 큐 생성
큐에 데이터를 넣는 키보드 핸들러와 데이터를 꺼내 사용하는 셸 코드가 잘 동작하려면 데이터의 구조가 먼저 정의되어야 합니다.
이번 내용에서는 키 정보를 전달하는 데 사용할 자료구조를 정의하고, 이를 사용하여 키를 저장하는 큐를 생성합니다.
셸 코드에서 키를 처리하려면 키에 해당하는 ASCII 코드와 키의 상태가 필요하기 때문에 키를 저장하는 자료구조에는 최소 ASCII 코드 필드와 키 상태 필드가 있어야 하고, 하드웨어에서 전달된 값도 필요하므로 스캔 코드 필드도 추가합니다.
아래는 세 가지 필드를 반영한 KEYDATA 자료구조입니다.

키를 저장하는 자료구조가 정의되었으니 이를 이용하여 큐를 생성합니다.
기존에 키보드를 활성화했던 kActivateKeyboard() 함수와 키 큐를 생성하는 기능을 묶어서 kInitializeKeyboard() 함수로 통합합니다.
아래는 kInitializeKeyboard() 함수의 코드입니다.
키 큐의 크기는 최대 100개로 넉넉하게 설정합니다.

→ 키보드 핸들러 수정
지금까지 키보드 핸들러는 메시지를 화면에 출력하고 EOI를 전송만 했을 뿐 사실상 핸들러가 없어도 OS가 동작하는 데 큰 문제가 없었지만, 이제 이 핸들러에 키를 읽어 큐에 삽입하는 핵심적인 역할을 부여합니다.
함수를 수정하는 일은 셸 코드의 키 처리 부분을 키보드 핸들러로 옮겨주고 키를 큐에 삽입하는 코드만 추가하면 됩니다.
아래는 키 처리 기능이 추가된 키보드 핸들러 코드입니다.

스캔 코드를 이용해서 ASCII 코드와 키 상태로 변환하는 부분과 해당 정보를 큐에 저장하는 부분은 재사용을 위해 kConvertScanCodeandPutQueue() 함수로 분리하여 작성했습니다.
→ 셸 코드 수정
키 값을 처리하는 부분이 셸 코드에서 키보드 핸들러 함수로 이동했으므로 키보드 컨트롤러 대신 큐를 참조하게 셸 코드를 수정해야 합니다.
키보드 컨트롤러를 확인하는 코드를 키가 저장된 큐와 데이터를 사용하게 변경하면 됩니다.
아래의 코드는 수정된 셸 코드입니다.
큐에서 키를 읽는 함수는 별도의 함수로 분리하여 재사용할 수 있게 했습니다.

→ 인터럽트로 인한 문제와 인터럽트 제어
인터럽트 기반으로 업그레이드한 키보드 디바이스 드라이버 코드에는 두 가지 문제가 있습니다.
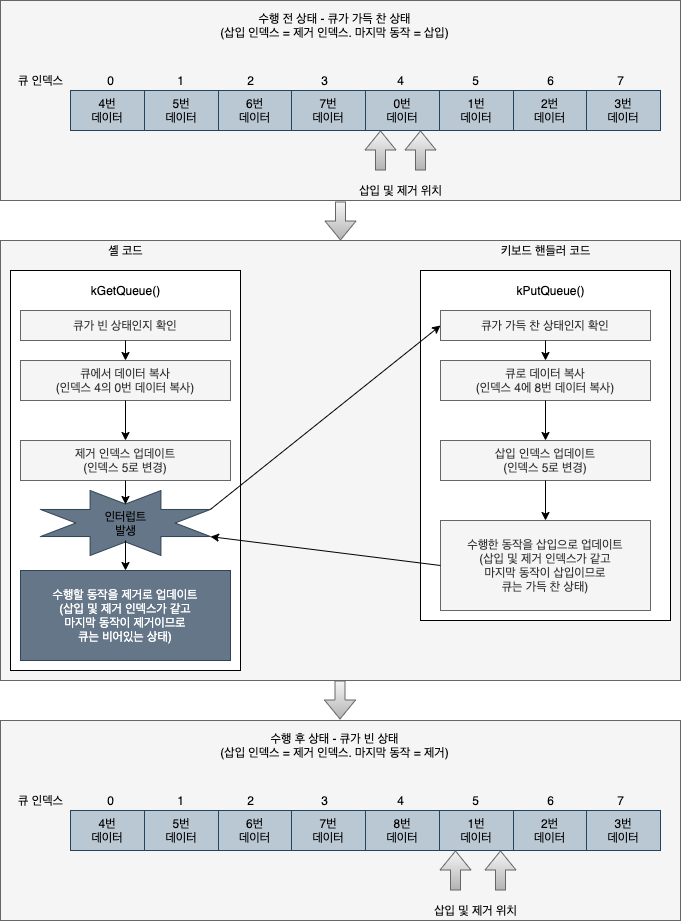
1. 큐에 삽입이나 제거를 수행할 때 인터럽트가 발생해서 인덱스에 문제가 생길 수 있습니다.
큐가 가득 찬 상태에서 셸 코드가 제거 동작을 수행할 때를 예로 들자면, 셸 코드가 제거 동작을 수행하여 제거 인덱스를 변경한 후, 수행한 명령이 제거라는 플래그를 설정하기 전에 인터럽트가 발생했다면, 인터럽트 핸들러가 수행되고 키보드 컨트롤러에서 수신한 키 데이터를 큐에 삽입하므로 마지막으로 수행한 명령이 삽입이라는 플래그가 설정됩니다.
하지만 문제는 인터럽트 처리를 완료하고 나서 실행 중인 코드로 복귀했을 때 발생합니다.
인터럽트 처리를 완료하고 나서 코드로 복귀했을 때 셸 코드는 아직 수행하지 못한 수행 명령 플래그를 제거로 업데이트하게 되는데, 만약 제거와 삽입이 순차적으로 실행되었다면 실제 큐의 상태는 제거 동작 수행 후 다시 삽입 동작이 수행되었으므로 가득 찬 상태여야 하지만, 인터럽트 때문에 큐에 수행된 마지막 명령이 제거로 업데이트되었으므로 큐의 상태는 가득 찬 상태가 아닌 완전히 비어있는 상태가 됩니다.
아래의 그림은 이런 상황을 나타낸 것입니다.
이런 문제는 멀티태스킹 환경에서 흔히 발생하는 동기화의 대표적인 예로 나중에 자세히 알아봅니다.
2. 키보드 활성화나 LED 컨트롤 같은 제어 명령의 ACK를 인터럽트가 가로챌 수 있는 문제입니다.
이전 코드는 키보드로 제어 명령을 전송하고 나서 ACK가 수신될 때까지 일정 시간을 기다려 성공 여부를 판단하도록 구현했었는데, 키보드가 보낸 ACK를 인터럽트 핸들러가 처리한다면 키보드 활성화 함수와 LED 컨트롤 함수는 ACK를 수신하지 못하므로 실패로 판단하게 됩니다.
위의 두 가지 문제의 공통된 원인은 인터럽트가 발생하지 않아야 하는 구간에서 인터럽트가 발생했기 때문입니다.
이러한 문제는 해당 구간에서 인터럽트를 발생하지 못하게 하면 해결할 수 있지만 무턱대고 진입 전에 인터럽트를 비활성화하고 수행 완료 후 활성화하면 해당 함수를 호출하기 전에 인터럽트가 이미 비활성화된 상태일지도 모르기 때문에 하면 안 됩니다.
가장 이상적인 방법은 이전의 인터럽트 상태를 저장했다가 복원하는 방법입니다.
아래는 인터럽트 플래그를 제어하는 데 사용할 kSetInterruptFlag() 함수입니다.
활성화나 비활성화를 수행할 때 이전 인터럽트 플래그의 상태를 반환하게 작성했으므로 복원할 때 이를 활용하면 됩니다.

인터럽트 방식의 문제점을 해결하는 방법을 알아보았으니 이제 키보드 디바이스 드라이버를 인터럽트 기반으로 수정합니다.
먼저 큐와 직접적인 관련이 있는 kConvertScanCodeAndPutQueue(), kGetKeyFromKeyQueue() 함수부터 살펴보자면, 두 함수를 수정한 예는 아래와 같습니다.
큐에 데이터를 삽입 또는 삭제할 때 인터럽트 플래그를 조작하여 작업을 수행하는 동안 인터럽트가 발생하지 않게 합니다.

ACK를 기다리는 동안 인터럽트를 비활성화하는 처리와 ACK 외에 다른 스캔 코드가 수신되었을 때 이를 ASCII 코드로 변환하여 큐에 삽입하는 방법을 고려해야 하기 때문에 ACK 처리와 관련된 부분은 키 큐를 처리하는 부분보다 좀 더 까다롭습니다.
ACK를 전송하기 전에 키보드가 눌려서 ACK 외에 다른 스캔 코드가 섞여 수신될 수 있기 때문에 이를 처리하려고 ACK를 대기하는 동안 수신된 키를 확인하여 큐에 삽입하는 kWaitForACKAndPutOtherScanCode() 함수를 추가합니다.

이제 kWaitForACKAndPutOtherScanCode() 함수로 ACK를 처리하도록 kActivateKeyboard(), kChangeKeyboardLED() 함수를 수정하는 일만 남았는데, 함수를 수정하려면 기존 코드에서 인터럽트 비활성화하는 부분을 추가하고, ACK를 처리하는 루프를 kWaitForACKAndPutOtherScanCode() 함수로 대체하면 됩니다.
두 함수의 수정 방법이 같으므로 kActivateKeyboard() 함수만 살펴봅니다.

'시작하지 말았어야 했던 것 > 64비트 멀티코어 OS' 카테고리의 다른 글
| 64비트 멀티코어 OS[12] - 2. 인터럽트, 예외 핸들러, 콘텍스트 그리고 PIC 컨트롤러 제어 코드와 핸들러 코드의 통합과 빌드 (0) | 2021.04.22 |
|---|---|
| 64비트 멀티코어 OS[12] - 1. PIC 컨트롤러와 PIC 컨트롤러 제어 (0) | 2021.04.21 |
| 64비트 멀티코어 OS[11] - 3. IDT, TSS 통합과 빌드 (0) | 2021.04.15 |
| 64비트 멀티코어 OS[11] - 2. GDT 테이블 교환과 TSS 세그먼트 디스크립터 추가 그리고 IDT 테이블 생성, 인터럽트, 예외 핸들러 등록 (0) | 2021.04.09 |
| 64비트 멀티코어 OS[11] - 1. 인터럽트와 예외 그리고 스택과 태스크 상태 세그먼트 (0) | 2021.04.08 |